Lean Data Architecture: Designing Simple Analytics Systems That Scale

Key Takeaways
- Many organizations adopt complex data tools too early. Platforms like Spark clusters, streaming systems, and lakehouses are often introduced before the data problems actually require them. This creates unnecessary infrastructure complexity and shifts engineering time toward platform management instead of delivering insights.
- Complex data platforms introduce hidden costs. Even when tools are open source, organizations still pay for training, infrastructure management, pipeline maintenance, and ongoing operations. Fully managed platforms reduce operational work, but their pricing can grow quickly as data volume increases.
- A lean data architecture focuses on solving real problems first. Instead of designing systems for hypothetical scale, the architecture matches current business needs and existing data volumes. The system can evolve later as the organization and its data requirements grow.
- Simple architectures can still support strong analytics. A lean architecture typically moves data through clear stages from raw data to structured datasets and finally to business ready models. Tools such as Python, DuckDB or Polars, PostgreSQL, and business intelligence platforms provide a reliable foundation without unnecessary complexity.
- Simplicity works especially well for small teams and moderate data volumes. When the data platform stays simple, engineers can spend less time managing infrastructure and more time producing insights that support business decisions.
The modern data tooling market is crowded. Each year new platforms promise faster pipelines, real-time analytics, or infinite scalability. Spark clusters, streaming frameworks, lakehouses, and fully managed warehouses all compete for attention. These tools solve real problems, but many organizations adopt them long before those problems actually exist.
When that happens, complexity grows faster than value. Infrastructure costs increase, systems become harder to maintain, and engineering teams spend more time managing platforms than delivering insight. Even when the tools themselves are open source, the real costs appear elsewhere: training, operational overhead, infrastructure management, and long-term maintenance.
Fully managed platforms sit on the opposite end of the spectrum. They make getting started easy, but the simplicity often shifts into pricing. What begins as a convenient solution can become expensive as data volume grows.
The lean data architecture takes a different approach. Instead of designing systems for hypothetical scale, it focuses on building architectures that match the current needs of the business. The goal is not to limit capability, but to remove unnecessary complexity while still delivering reliable analytics. For many small and mid-sized organizations, that simpler architecture is more than enough.
Principles of a Lean Data Architecture
The lean data architecture is guided by a small set of principles designed to keep data systems simple, maintainable, and aligned with business needs.
Choose Tools That Match the Workload
Data infrastructure should reflect the scale and complexity of the problem it is solving. Many analytical workloads can be handled efficiently with modern local processing engines and relational databases. By selecting tools that match the current workload, teams can keep systems easier to operate while still supporting meaningful analytics.
As data volume and requirements grow, the architecture can evolve to incorporate more advanced infrastructure when it becomes justified.
Prioritize Maintainability
Data systems should be understandable by the engineers responsible for maintaining them. Technologies with large communities, clear documentation, and familiar programming models make systems easier to operate over time.
When a new engineer joins the team, they should be able to understand the structure of the pipelines and data models without needing to learn an entirely new platform.
Build for Real Workloads
It is common for organizations to design platforms around projected scale rather than actual usage. A lean architecture instead evolves alongside the business. Systems should be designed around the data volumes and performance requirements that exist today, with room to expand when growth demands it.
This approach avoids unnecessary infrastructure while still allowing the system to grow naturally.
Align Data Engineering With Business Needs
Effective data engineering sits at the intersection of three forces:
- The shape and structure of the data
- The business questions being answered
- The engineering approach used to deliver those answers
Strong architectures balance these constraints rather than optimizing purely for technical sophistication. The goal is not to build the most complex platform, but to deliver reliable information that supports decision making.
Lean Data Architecture
The lean data architecture organizes the data lifecycle into a small number of clearly defined stages. Each stage has a focused responsibility and uses tools that are well suited for that task.
Below is a simplified view of the architecture.
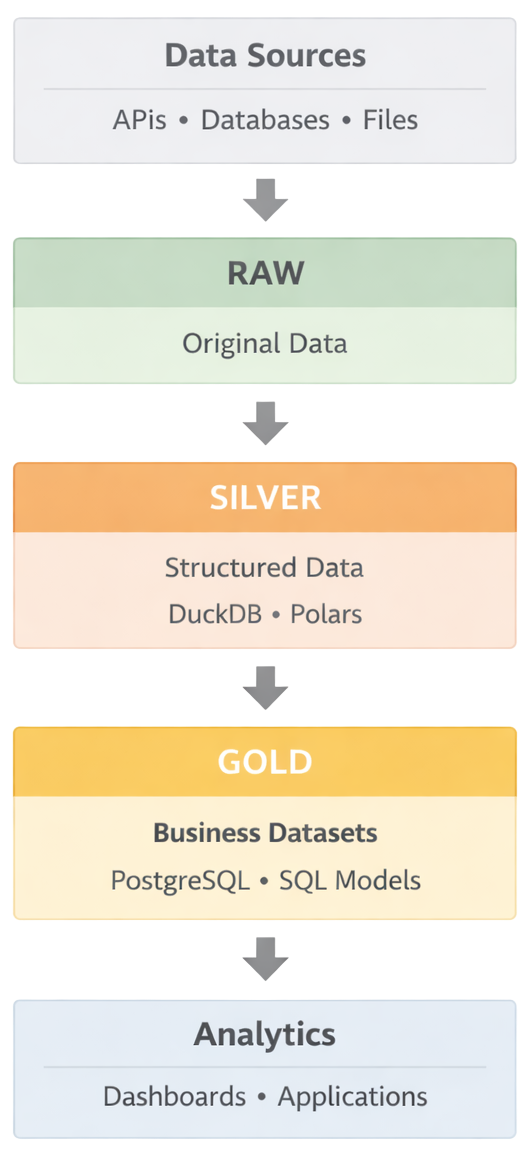
The diagram illustrates how data moves from operational systems to analytical outputs.
Data is first collected from source systems such as APIs, internal services, or transactional databases. Python-based ingestion pipelines extract the data and store it in a raw storage layer that preserves the original records. This layer acts as a durable archive and allows pipelines to be rebuilt or reprocessed when necessary.
From there, processing engines such as DuckDB or Polars transform the raw data into structured datasets. These transformations clean the data, enforce schemas, and prepare it for analytical use.
The transformed data is then loaded into PostgreSQL, which acts as the central analytical store. At this stage the data is structured, indexed, and ready to support analytical queries.
On top of the analytical database, SQL models organize the data into business-aligned datasets. These models define metrics, relationships, and aggregations that reflect how the organization understands its operations.
Finally, the curated datasets power dashboards, reports, and internal data applications used by analysts and business teams.
While the architecture may appear simple, each layer plays an important role in maintaining reliability, clarity, and maintainability within the system.
Core Technologies in a Lean Data Stack
A lean data stack begins with a small set of reliable tools that cover the most common data engineering needs: ingestion, transformation, storage, and reporting. These technologies provide a practical starting point for building analytics systems without introducing unnecessary complexity.
For many organizations, this foundation is enough to support years of growth. As requirements evolve, additional tools can be introduced gradually without redesigning the entire architecture.
Python
Python typically serves as the foundation of the data pipeline layer. It is widely used for extracting data from APIs, interacting with databases, automating ingestion workflows, and running transformation pipelines.
Its large ecosystem and strong data tooling make it well suited for building flexible data workflows without requiring specialized infrastructure.
Analytical Processing Libraries
Within Python, analytical libraries such as DuckDB and Polars provide fast and efficient data processing capabilities.
DuckDB offers a high-performance analytical database engine that can query large datasets directly from files such as Parquet. Polars provides a fast dataframe engine optimized for modern analytical workloads.
These tools allow engineers to transform and analyze large datasets on a single machine while keeping the surrounding infrastructure simple.
PostgreSQL
PostgreSQL acts as the central analytical database. It stores structured datasets produced by transformation pipelines and provides a reliable interface for querying, modeling, and reporting.
Because PostgreSQL is widely understood and integrates well with many tools, it provides a stable foundation for analytical workloads.
Business Intelligence Tools
Visualization tools such as Power BI provide the reporting and exploration layer of the stack. These platforms allow analysts and business users to build dashboards, explore datasets, and share insights across the organization.
The goal at this stage is to make trusted data easily accessible rather than building a complex reporting platform.
Data Flow Through the Lean Data Architecture
Data in the lean architecture moves through a small number of clearly defined stages. Each stage has a focused responsibility and helps maintain clarity as the system grows.
The model used here follows a common pattern often described as Raw, Silver, and Gold layers. These layers represent the progression from captured data to business-ready datasets.
The raw layer preserves the original records from source systems. The silver layer transforms that data into structured and queryable tables. The gold layer organizes the data into business-aligned datasets that support reporting, dashboards, and applications.
Separating these responsibilities helps ensure that ingestion, transformation, and business modeling remain independent from one another.
Raw Layer: Reliable Data Capture
The raw layer is responsible for capturing data from source systems and storing it without significant modification.
At this stage the primary goal is reliability. The raw layer stores the original data exactly as it was received from the source system. Keeping this unmodified copy allows pipelines to be reprocessed if transformations need to change later.
A typical ingestion workflow includes:
- Extracting data from APIs, operational databases, or third-party systems
- Writing the extracted data to raw storage
- Tracking ingestion state so pipelines can resume safely
Tracking ingestion state is particularly important when working with APIs that do not provide reliable update timestamps. In those cases, pipelines must track their own progress to avoid reprocessing large datasets.
A simple solution is storing ingestion metadata in a small PostgreSQL table. Each job can record information such as:
- Last processed timestamp
- Last processed ID
- Extraction status
- Job execution time
This metadata allows ingestion pipelines to run incrementally while maintaining reliability.
Silver Layer: Structured and Queryable Data
The silver layer transforms raw data into structured datasets that are easier to query and analyze.
At this stage data is cleaned, normalized, and organized into relational tables. The goal is not yet to define business metrics, but to ensure that the data is consistent and analytically usable.
In this layer, raw datasets are cleaned, joined, and reshaped into structured tables. Tools such as DuckDB or Polars allow these transformations to be performed efficiently on a single machine while keeping the surrounding system simple.
Once transformations are complete, the structured tables are loaded into PostgreSQL where they become accessible for analytical queries.
Several design practices are useful in this layer:
- Define clear primary and foreign keys
- Use consistent naming and structure across related tables so joins and relationships remain predictable
- Create indexes based on query patterns
- Enforce schemas before loading data
- Use table partitioning only when datasets grow large enough to require it
The silver layer represents data that engineers trust from a technical perspective, even though it may not yet reflect the final business definitions used for reporting.
Gold Layer: Business-Aligned Data Models
The gold layer turns structured data into datasets that reflect how the business actually operates.
At this stage the focus shifts from engineering concerns to business definitions. Tables and views in this layer represent the metrics and summaries that analysts, dashboards, and applications rely on for reporting.
Examples of gold layer datasets include:
- Daily revenue summaries
- Sales performance by product or region
- Inventory turnover summaries
These datasets are intentionally curated so that teams across the organization rely on consistent definitions when analyzing performance.
In many cases, these models can be implemented as SQL views built on top of the structured tables in the silver layer. As queries become more complex or datasets grow larger, those views can be materialized to improve performance.
Operating the Lean Data Architecture
A simple architecture still requires operational practices to keep the system reliable as it grows. Data modeling, quality checks, governance, and deployment processes help ensure that the datasets produced by the pipeline remain trustworthy and maintainable over time.
The goal of these practices is not to introduce additional complexity, but to provide structure as the number of datasets and pipelines increases.
Data Modeling and Transformation
As the number of datasets grows, it becomes useful to organize SQL transformations in a structured way. Modeling frameworks such as dbt or SQLMesh help manage these transformations by treating datasets as version-controlled models.
In this approach, each dataset is defined as a SQL model that builds on top of upstream tables. Dependencies between models are tracked automatically, which allows transformations to run in a predictable order and makes the data pipeline easier to understand.
These frameworks also provide features such as documentation, lineage tracking, and built-in testing. As the number of datasets increases, these capabilities help teams maintain clarity about how data is produced and how different tables relate to one another.
Many teams begin with simple SQL scripts and introduce a modeling framework only once the number of transformations grows large enough to justify additional structure. This approach keeps the system simple early on while still allowing it to scale as the data platform matures.
Data Quality
Reliable analytics depends on consistent data quality. Simple validation checks can catch many issues before they reach dashboards or reports.
These checks ensure that the data being produced by pipelines matches expectations and remains consistent over time.
Common validation checks include:
- Ensuring key fields are not null
- Verifying relationships between related tables
- Confirming expected row counts or data freshness
These checks can be implemented using SQL assertions, modeling framework tests, or lightweight validation scripts within pipelines.
The goal is not to build a complex monitoring system, but to ensure that core datasets remain reliable and trustworthy as they move through the pipeline.
Data Governance
Even simple data systems benefit from basic governance practices. As the number of datasets grows, teams need shared definitions and clear ownership to prevent confusion.
Governance practices help ensure that everyone in the organization understands how data is defined and where it comes from.
Important practices include:
- Documenting dataset definitions and business metrics
- Establishing clear ownership of tables and pipelines
- Maintaining consistent metric definitions across reports and dashboards
Documentation tools, modeling frameworks, or lightweight data catalogs can help teams track dataset definitions and lineage as the system evolves.
Deployment and Scheduling
Data pipelines need a reliable way to run and update as new data arrives. In a lean architecture, deployment is typically handled using simple automation rather than large orchestration platforms.
Many teams run pipelines using scheduled tasks such as cron jobs, containerized workloads, or lightweight CI/CD pipelines. These approaches provide reliable execution without requiring complex infrastructure.
As systems grow more complex, teams may introduce additional orchestration tools, but many organizations operate successfully with simple scheduling for a long time.
How to Know if a Lean Data Architecture Is the Right Fit
A lean data architecture works best when the complexity of the data platform matches the scale of the organization operating it.
For many teams, a small number of well-designed pipelines and clearly defined datasets are enough to support analytics for years. But not every organization benefits from the same architecture. A few simple questions can help determine whether a lean approach is likely to work well.
Your Data Volume Is Manageable
If your datasets comfortably fit on a single machine and most analytical queries complete in seconds, a simpler architecture is often sufficient.
Modern analytical tools can process millions or even hundreds of millions of rows efficiently without requiring distributed infrastructure.
Your Team Is Small (or your organization is starting from scratch)
When a small group of engineers is responsible for maintaining the data platform, systems that rely on widely understood tools tend to be easier to operate and evolve.
Simple architectures allow teams to focus on solving business problems rather than managing infrastructure.
Your Analytics Workloads Are Mostly Batch
If most reporting is based on daily or hourly updates rather than real-time streaming pipelines, a lean stack can support those workflows without introducing additional systems.
When It May Help to Bring in Outside Perspective
Designing a data platform often involves trade-offs between performance, complexity, and long-term maintainability. In some cases, the challenge is not choosing tools but deciding how the system should evolve as data needs grow.
Teams sometimes benefit from an external perspective when they are:
- Rebuilding an existing data platform
- Migrating away from legacy analytics infrastructure
- Trying to simplify a stack that has become difficult to maintain
- Deciding whether more advanced infrastructure is actually necessary
These decisions are often easier when they are informed by experience across different architectures and environments.
If you're evaluating how to design a data platform or simplify an existing analytics stack, this is the type of work I focus on. I'm always open to helping teams think through architecture decisions and practical implementation.